

AI with Python – Reinforcement Learning
In this chapter, you will learn in detail about the concepts reinforcement learning in AI with Python.
Basics of Reinforcement Learning
This type of learning is used to reinforce or strengthen the network based on critic information. That is, a network being trained under reinforcement learning, receives some feedback from the environment. However, the feedback is evaluative and not instructive as in the case of supervised learning. Based on this feedback, the network performs the adjustments of the weights to obtain better critic information in future.
This learning process is similar to supervised learning but we might have very less information. The following figure gives the block diagram of reinforcement learning −
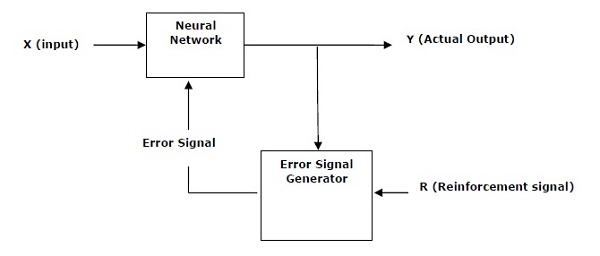
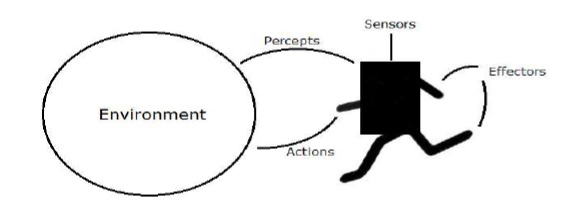
Building Blocks: Environment and Agent
Environment and Agent are main building blocks of reinforcement learning in AI. This section discusses them in detail −
Agent
An agent is anything that can perceive its environment through sensors and acts upon that environment through effectors.
-
A human agent has sensory organs such as eyes, ears, nose, tongue and skin parallel to the sensors, and other organs such as hands, legs, mouth, for effectors.
-
A robotic agent replaces cameras and infrared range finders for the sensors, and various motors and actuators for effectors.
-
A software agent has encoded bit strings as its programs and actions.
Agent Terminology
The following terms are more frequently used in reinforcement learning in AI −
-
Performance Measure of Agent − It is the criteria, which determines how successful an agent is.
-
Behavior of Agent − It is the action that agent performs after any given sequence of percepts.
-
Percept − It is agent’s perceptual inputs at a given instance.
-
Percept Sequence − It is the history of all that an agent has perceived till date.
-
Agent Function − It is a map from the precept sequence to an action.
Environment
Some programs operate in an entirely artificial environment confined to keyboard input, database, computer file systems and character output on a screen.
In contrast, some software agents, such as software robots or softbots, exist in rich and unlimited softbot domains. The simulator has a very detailed, and complex environment. The software agent needs to choose from a long array of actions in real time.
For example, a softbot designed to scan the online preferences of the customer and display interesting items to the customer works in the real as well as an artificial environment.
Properties of Environment
The environment has multifold properties as discussed below −
-
Discrete/Continuous − If there are a limited number of distinct, clearly defined, states of the environment, the environment is discrete , otherwise it is continuous. For example, chess is a discrete environment and driving is a continuous environment.
-
Observable/Partially Observable − If it is possible to determine the complete state of the environment at each time point from the percepts, it is observable; otherwise it is only partially observable.
-
Static/Dynamic − If the environment does not change while an agent is acting, then it is static; otherwise it is dynamic.
-
Single agent/Multiple agents − The environment may contain other agents which may be of the same or different kind as that of the agent.
-
Accessible/Inaccessible − If the agent’s sensory apparatus can have access to the complete state of the environment, then the environment is accessible to that agent; otherwise it is inaccessible.
-
Deterministic/Non-deterministic − If the next state of the environment is completely determined by the current state and the actions of the agent, then the environment is deterministic; otherwise it is non-deterministic.
-
Episodic/Non-episodic − In an episodic environment, each episode consists of the agent perceiving and then acting. The quality of its action depends just on the episode itself. Subsequent episodes do not depend on the actions in the previous episodes. Episodic environments are much simpler because the agent does not
need to think ahead.
Constructing an Environment with Python
For building reinforcement learning agent, we will be using the OpenAI Gym package
which can be installed with the help of the following command −
>pip install gym
There are various environments in OpenAI gym which can be used for various purposes.
Few of them are Cartpole-v0, Hopper-v1, and MsPacman-v0. They require different
engines. The detail documentation of OpenAI Gym can be found on https://gym.openai.com/docs/#environments.
The following code shows an example of Python code for cartpole-v0 environment −
>import gym
env = gym.make('CartPole-v0')
env.reset()
for _ in range(1000):
env.render()
env.step(env.action_space.sample())

You can construct other environments in a similar way.
Constructing a learning agent with Python
For building reinforcement learning agent, we will be using the OpenAI Gym package as shown −
import gym env = gym.make('CartPole-v0') for _ in range(20): observation = env.reset() for i in range(100): env.render() print(observation) action = env.action_space.sample() observation, reward, done, info = env.step(action) if done: print("Episode finished after {} timesteps".format(i+1)) break
Observe that the cartpole can balance itself.